Week 1 — Feb 12: Introduction, History & Training Overview
UCLA ECE RLHF Reading Group
| Chapters: 1-3 | Presenter: Shreyas |
Note: Content, figures, and examples in these notes are drawn from Nathan Lambert’s RLHF Book and referenced papers. These are reading group notes, not original work.
Chapter 1: Introduction — Key Takeaways
What RLHF actually does
- RLHF operates at the response level (not per-token like SFT) — it tells the model what a better response looks like via contrastive feedback
- The core contribution is style and behavioral shaping — warmth, formatting, safety, engagement — things that SFT alone can’t reliably instill
- RLHF generalizes far better across domains than SFT (Kirk et al. 2023, Chu et al. 2025)
Three types of post-training
- SFT/IFT — teaches format, instruction-following. Learns features in language
- Preference Fine-tuning (PreFT) — aligns to human preferences. Learns style and subtle preferences. This is where RLHF lives
- RLVR — RL with verifiable rewards for reasoning domains. Newest, fastest-evolving
The Elicitation Theory of Post-Training
- Post-training doesn’t teach new knowledge — it extracts latent capabilities from the base model
- Analogy: base model = F1 chassis, post-training = aerodynamics and systems tuning
- The Superficial Alignment Hypothesis (LIMA paper) gets the direction right but undersells the impact — post-training does far more than superficial style changes, especially with RLVR for reasoning
Why this matters
- Lambert argues RLHF was the technique that enabled ChatGPT’s success
- Companies that embraced RLHF early (Anthropic, OpenAI) built lasting advantages
- The field went through a skepticism phase (“SFT is enough”) that delayed open-source progress
Chapter 2: Key Related Works — Timeline
Phase 1: Origins (pre-2018)
- TAMER (2008) — humans iteratively score agent actions → reward model → policy. The proto-RLHF
- Christiano et al. 2017 — the primary reference. RLHF on Atari trajectories. Showed preference feedback can beat direct environment interaction
- Key shift: reward models proposed as tool for studying alignment, not just solving RL tasks (Leike et al. 2018)
Phase 2: Language Models (2019-2022)
- Ziegler et al. 2019 — first RLHF on LMs. Already had reward models, KL penalties, feedback loops — strikingly similar to modern work
- Applied to: summarization (Stiennon 2020), instruction following (InstructGPT/Ouyang 2022), web QA (WebGPT), dialogue (Sparrow)
- Foundational concepts established: reward model over-optimization (Gao et al.), red teaming (Ganguli et al.)
Phase 3: ChatGPT Era (2023+)
- ChatGPT explicitly credited RLHF. Used in Claude, Llama 2/3, Nemotron, Tülu 3
- DPO (May 2023) → didn’t take off until fall 2023 when the right learning rates were found (Zephyr-Beta, Tülu 2)
- Field expanding into: process reward models, direct alignment algorithms, RLVR for reasoning
Chapter 3: Training Overview — Core Concepts
The RLHF objective
Standard RL: maximize expected reward over trajectories RLHF simplification: no state transitions, response-level (bandit) rewards, learned reward model
\[J(\pi) = \mathbb{E}[r_\theta(x, y)] - \beta \cdot D_{\text{KL}}(\pi \parallel \pi_{\text{ref}})\]Three key differences from standard RL:
- Reward function → reward model (learned, not environmental)
- No state transitions (prompt in, completion out — single step)
- Response-level rewards (bandit-style, not per-timestep)
The KL penalty
- Prevents the policy from drifting too far from the reference (initial) model
- β controls the trade-off: too low → over-optimization/reward hacking, too high → no learning
- The “KL budget” concept — how much deviation from the base model are you willing to spend?
Three canonical recipes (increasing complexity)
InstructGPT (2022): SFT (10K) → Reward Model (100K pairs) → RLHF (100K prompts) Simple, three-stage. The template everything builds on.
Tülu 3 (2024): SFT (1M synthetic) → On-policy DPO (1M pairs) → RLVR (10K prompts) Much more data, synthetic data-heavy, adds RLVR for reasoning.
DeepSeek R1 (2025): Cold-start SFT (100K+ reasoning) → Large-scale RLVR → Rejection sampling → Mixed RL Reasoning-first. RL is the centerpiece, not an afterthought. Represents the current frontier.
The trend: more stages, more data, more RL, reasoning-centric.
Discussion Questions
-
The Elicitation Theory vs. Superficial Alignment: Lambert argues post-training extracts deep capabilities, not just surface style. But LIMA showed you can get surprisingly far with 1K examples. Where’s the truth? Is there a threshold where more preference data stops helping and you need a fundamentally different signal (like RLVR)?
-
Why did it take so long for DPO to work? The math was published in May 2023 but the first good models weren’t until fall 2023 — and the fix was just a lower learning rate. What does this tell us about the gap between theory and practice in post-training? What other “obvious in hindsight” practical details might be hiding in current methods?
-
The three recipes (InstructGPT → Tülu 3 → DeepSeek R1) show a clear trend toward more RL. Is RLHF (preference-based) becoming less important relative to RLVR (verifiable rewards)? Or do they serve fundamentally different purposes — preferences for style/safety, verifiable rewards for capabilities?
-
The KL penalty is doing a lot of work. It’s the main thing preventing reward hacking and model collapse. But it also limits how far the model can improve. How should we think about setting β? Is there a principled way, or is it mostly empirical?
-
Open vs. closed gap: Lambert notes companies that embraced RLHF early (Anthropic) built lasting advantages, and that open-source was stuck in a “SFT is enough” phase. As of 2025/2026, has the open-source community closed this gap? What’s still missing?
Key Equations to Know
The RLHF objective — maximize reward while staying close to the reference policy:
\[J(\pi) = \mathbb{E}[r_\theta(x,y)] - \beta \, D_{\text{KL}}(\pi \parallel \pi_{\text{ref}})\]Trajectory distribution in standard RL — contrast with the simplified RLHF bandit setup:
\[p_\pi(\tau) = \rho_0(s_0) \prod_{t} \pi(a_t \mid s_t) \, p(s_{t+1} \mid s_t, a_t)\]Notes
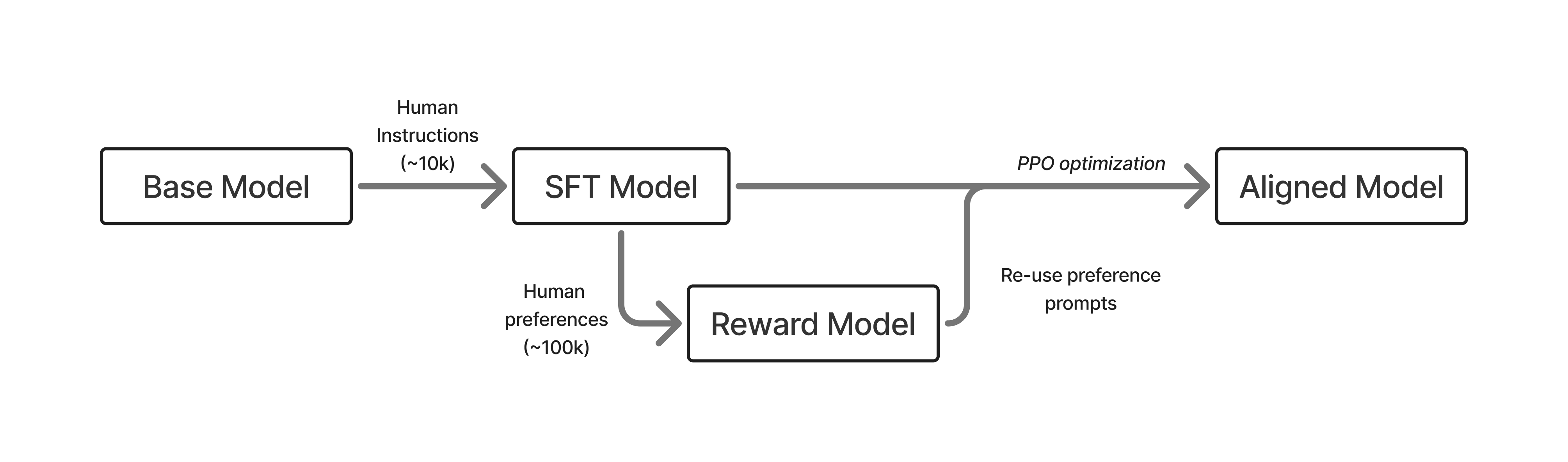
- Core intuition for RLHF: It’s a way to bake in “human taste” into AI systems. These preferences are hard to specify — you can’t write them as a simple loss function like next-token prediction. But humans can compare outputs (“A is better than B”), and RLHF turns that comparative signal into a training objective via reward models. It’s “I know it when I see it” turned into a gradient.
- Where does preference data come from? You sample multiple responses from the SFT model, then humans rank/compare them. The SFT model is the right source — pre-SFT outputs are incoherent garbage, post-SFT you get responses in the right format but with meaningful quality variance for humans to judge. Modern setups make this iterative (on-policy sampling, AI feedback instead of humans).
- The reward model is a proxy for the human. You can’t have a human rating every sample during RL training, so the RM learns to approximate human judgment from a finite set of comparisons. This proxy nature is the root of RLHF’s central challenge: over-optimization (the policy exploits RM quirks that don’t reflect real preferences). The KL penalty exists to manage this gap.
- The KL penalty and what it implies about learning:
- The reference model (π_ref) is the SFT model, not the base model — it’s frozen throughout RL training as a fixed anchor.
- The RLHF objective uses reverse KL $D_{\text{KL}}(\pi \parallel \pi_{\text{ref}})$, which is mode-seeking — it penalizes the policy for putting mass where the reference has low probability. The policy sharpens onto the best modes of the reference but cannot generate things the reference would never say.
- Contrast with SFT, which minimizes forward KL (cross-entropy with data) — mass-covering, producing broad but sometimes unfocused outputs.
- This means RLHF is fundamentally redistributing existing probability mass — upweighting good behaviors, downweighting bad ones — not creating new capabilities from scratch. This is exactly why the Elicitation Theory holds: the base model’s pretraining determines the ceiling.
- Open question: DeepSeek R1-Zero develops chain-of-thought reasoning through RL that the base model never visibly exhibited. Is that truly new, or was there always a tiny probability that RL amplified?
- RLHF is on-policy. The policy generates responses, the RM scores them, the policy is updated, and the next batch comes from the updated policy — always learning from its own current behavior. This is why RLHF is expensive: every step requires generation (slow) + RM scoring + reference model for KL, so potentially three models in memory at once. DPO (Ch 8) avoids this by being off-policy — it works on a pre-collected dataset with no generation loop, which is much cheaper but the signal can become stale as the policy changes.
- Early open-source post-training (Self-Instruct era): Before RLHF was widely adopted in open-source, models like Alpaca, Vicuna, and Dolly used the Self-Instruct approach — take a small number of human-written instruction-response pairs, use a strong model (GPT-3.5) to generate thousands more synthetic examples in the same style, then SFT a weaker model (LLaMA) on the result. Alpaca: 175 seeds → 52K synthetic examples → fine-tune LLaMA for ~$600. Worked great for vibes, but this was all SFT on synthetic data — no reward model, no RL, no preference learning. The benchmarks at the time (AlpacaEval, MT-Bench) couldn’t distinguish this from real RLHF, which led the open-source community to underestimate the importance of RLHF for about a year.
- Why preference fine-tuning is harder than SFT: Two reasons. (1) You’re optimizing a proxy of the true objective (the RM) rather than the real thing — SFT just imitates target outputs directly, no indirection. (2) Preference data is inherently noisier — humans disagree with each other, preferences are relative not absolute (“A is better than B” doesn’t mean A is good), and annotation is subjective and cognitively taxing. Both factors compound to make RLHF more complex than SFT.
- What post-training actually changes (base model vs. post-trained):
- Llama 3.1 405B Base given “The president of the united states in 2006 was”: produces a rambling continuation mixing facts with random web metadata — dates, legislation, encyclopedia fragments. It’s doing next-token prediction, continuing the document, not answering a question.
- Tülu 3 405B (post-trained) given the same prompt: “George W. Bush was the president of the United States in 2006. He served two terms in office, from January 20, 2001, to January 20, 2009.” Concise, direct, conversational. This shift from document-completion to question-answering is what post-training does.
Action Items
- Everyone confirms
rlhf-book/codesetup works (uv sync) before next week - Assign Ch 4+5 presenter
- Next week: read Ch 4 (Instruction Tuning) + Ch 5 (Reward Models) — Ch 4 is short conceptual setup, Ch 5 is the first real technical deep-dive
- Hands-on: try running a reward model training before the meeting:
cd rlhf-book/code WANDB_MODE=disabled uv run python -m reward_models.train_orm --samples 400 --epochs 2 - Optional: skim the InstructGPT paper (Ouyang et al. 2022) and Christiano et al. 2017 for deeper context